Data Jockey is a FLOSS project for digital djing.
Data Jockey is largely centered around a database of music and information about this music. The music is provided by the user. The information about the music is gathered from audio file meta data (information from id3 tags), computed through feature extraction techniques, and also provided directly by the user.
Numerical data items, usually computed, are referred to as 'descriptors'. Textual data items, usually provided by the user, are referred to as 'tags'. Tags allow users to provide their own organization schemes. For instance, users may decide to associate songs with 'theme' tags. These tags may indicate which songs have which themes.
These tags and descriptors provide user of Data Jockey with several avenues for content retrieval. The ultimate goal is to find music to include into a DJ mix. Instead of simply searching for music based on the title, artist or album of a work, users can search for music based on qualities of the music itself.
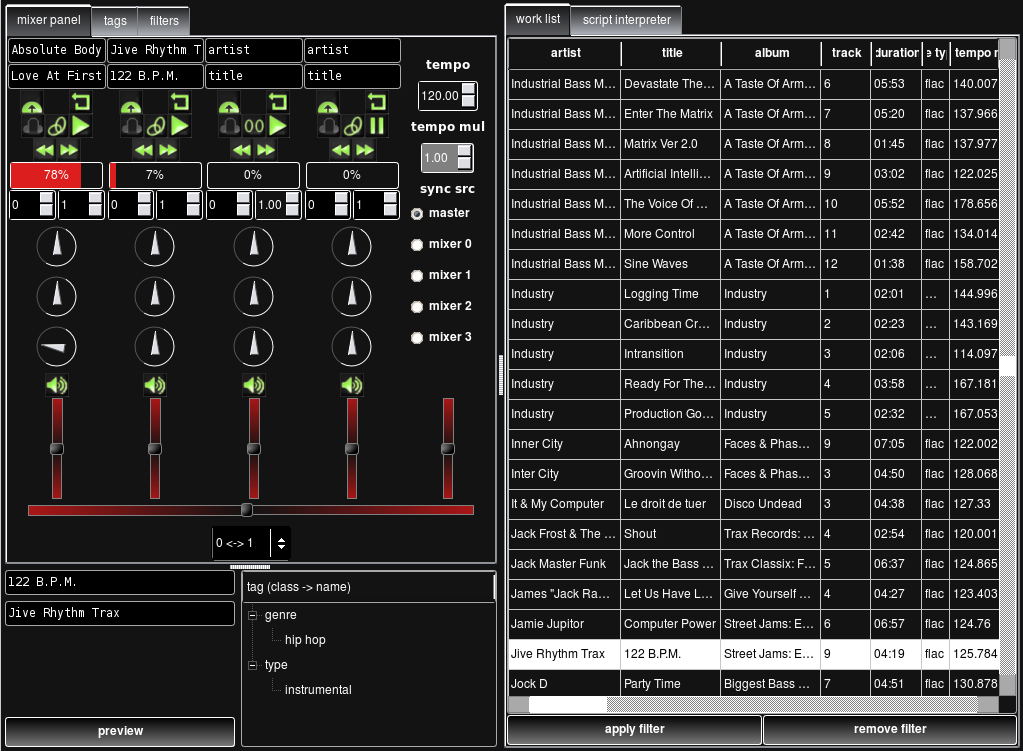
The Data Jockey user interface consists of a visualization of the user's music database and music meta-data and a audio mixer-panel like tool for combining works. Data Jockey automatically tempo matches works which hopefully allows users to focus more on finding interesting juxtapositions than the technical elements of combining works.
There are a few 'filters' provided which allow users to filter the works they view based on tags selected in a tag visualization, or based on the relationship between a song's original tempo and the current tempo of a mix. Users will also be able to create custom filters which can react to the current state of a mix. For instance, a user might have a filter which displays only works which have some tag or descriptor relationship with works which are currently audible in a mix. Eventually I would like to keep a history of songs in a mix so that filters might react to more than just the current state, but also previous states.
{kind=link}